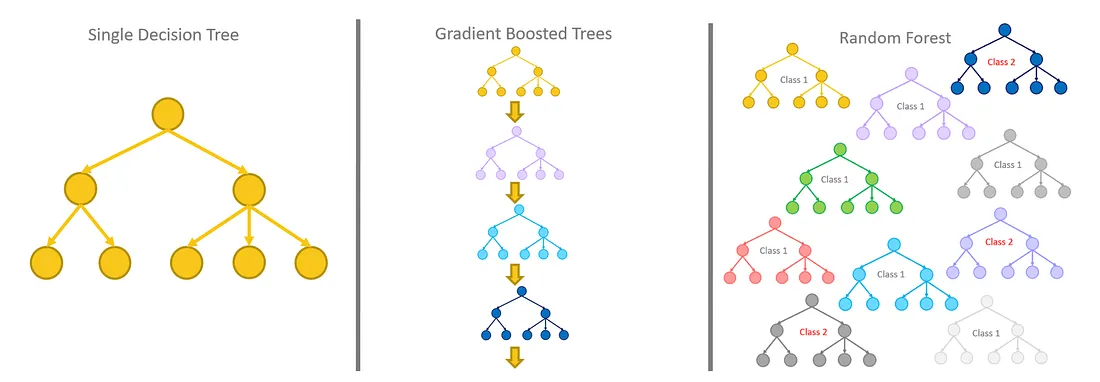
Random Forest는 여러 결정트리를 묶어 과적합을 회피할 수 있는 앙상블 방법 중 하나로 예측을 잘하는 (과적합가능성이 있는)트리들을 평균내어 과적합을 줄입니다. Random forest의 Random은 트리 생성 시 무작위성이 들어감을 의미하는데 트리 생성 시 데이터 중 일부를 무작위로 선택하게 되고 노드 분할 시 무작위로 후보 특성을 선택하게 됩니다.
Random Forest 방법론은 전체 특징 중 랜덤으로 일부 특징만 선택해 하나의 결정 트리를 만들고 이 과정을 사용자가 원하는 값만큼 반복해 여러 개의 의사 결정 트리를 만드는 방식으로 구성됩니다. 이렇게 여러 결정 트리들이 내린 예측 값들 중, 가장 많이 나온 값을 최종 예측값으로 정합니다.
*배깅방식으로 샘플링된 데이터마다 의사결정나무가 예측한 결과를 소프트보팅하여 최종 예측 결론 얻습니다.
랜덤 포레스트는 분류 및 회귀문제에 모두 사용 가능되며 결측치를 다루기 쉽고 대용량 데이터 처리에 효과적입니다. 또 모델의 노이즈를 심화시키는 오버피팅 문제를 회피하여, 모델 정확도를 향상시키고분류 모델에서 상대적으로 중요한 변수를 선정 및 Ranking 가능하다는 장점이 있습니다.
다만 개별 트리 분석이 어렵고 트리 분리가 복잡해지는 경향이 존재하며 텍스트 데이터와 같이 차원이 크고 희소한 데이터에는 성능이 미흡합니다. 또 훈련 시 메모리 소모가 크고 Train data를 추가해도 모델 성능 개선이 어렵다는 단점이 있습니다.
Bagging 방식을 사용하는 랜덤 포레스트와 Boosting 방식을 사용하는 그레디언트 부스팅의 차이
Scikit-learn 예제 코드 및 파라미터https://wooono.tistory.com/115
⇒트리는 작은 편향과 큰 분산을 가지기 때문에 깊이 성장한 트리에는 과적합이 발생합니다. 부트스트랩 과정은 트리들의 편향은 그대로 유지하면서 분산을 감소시키므로 포레스트의 성능을 향상시킵니다. 이는 트리들이 상관화되지 않게 되면서 노이즈에 강인해진다는 의미입니다.
따라서 배깅은 서로 다른 데이터셋들에 대해 훈련시킴으로써 트리들을 비상관화시켜주는 과정이라고 할 수 있습니다.