[4.1 분류(Classification)의 개요]
분류: 학습데이터로 주어진 데이터의 피처와 레이블값을 머신러닝 알고리즘으로 학습해 모델을 생성하고, 이렇게 생성된 모델에 새로운 데이터 값이 주어졌을 때 미지의 레이블 값을 예측하는 것
즉, 기존 데이터가 어떤 레이블에 속하는지 패턴을 알고리즘으로 인지한 뒤에 새롭게 관측된 데이터에 대한 레이블을 판별하는 것
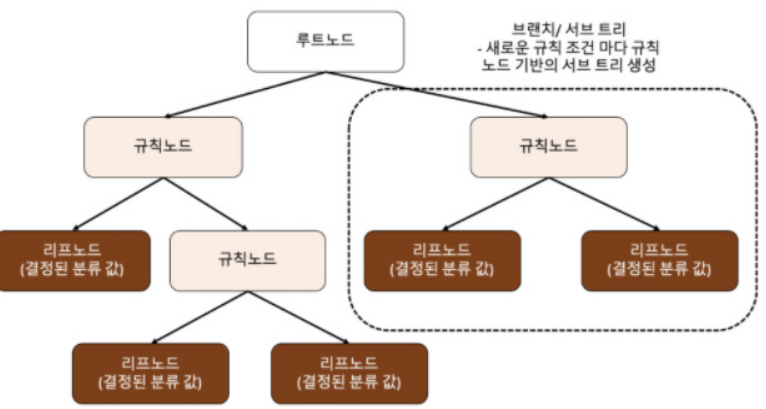
결정트리: 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내는 트리 기반의 분류 규칙 / 분류 기준 잘 정해서 과적합 줄여야 함
[4.2 결정 트리]
<정보의 균일도 측정 방법>
정보 이득: 엔트로피 개념 기반, 엔트로피는 주어진 데이터 집합의 혼잡도 의미, 서로 다른 값이 섞여 있으면 엔트로피가 높음, 정보이득 = 1 - 엔트로피 지수, 정보 이득 높을수록 균일
지니계수: 0이 가장 평등, 1이 가장 불평등, 지니계수 높을수록 불균일
DecisionTreeClassifier: 정보 이득이 높거나 지니 계수가 낮은 조건을 찾아서 자식 트리 노드에 걸쳐 반복적으로 분할한 뒤, 데이터가 모두 특정 분류에 속하게 되면 멈추고 분류 결정
쉽고 직관적이고 가공 안해도 괜찮지만 과적합으로 성능이 떨어질 수 있다
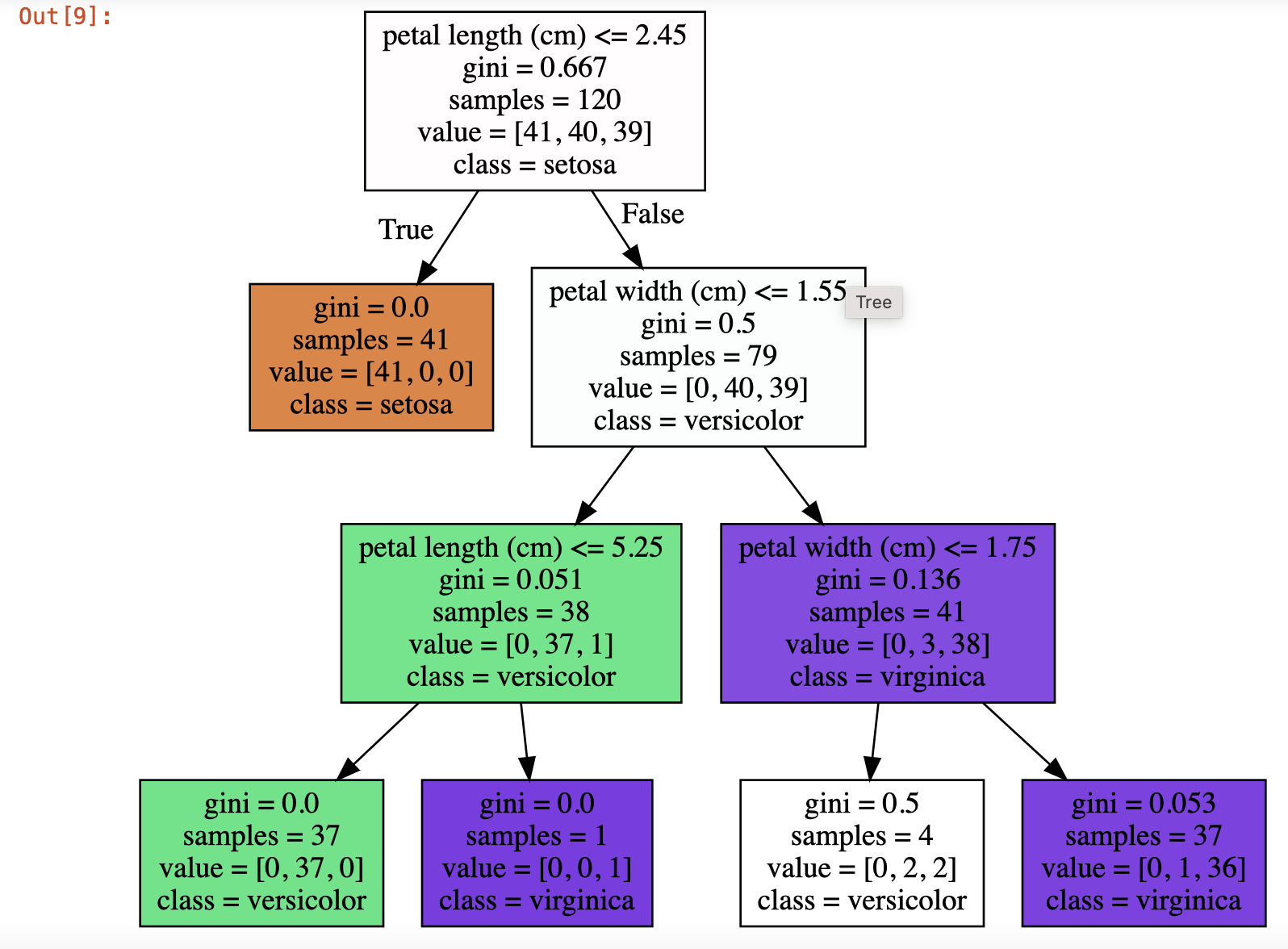
Graphviz 이용