[7.1 K-평균 알고리즘 이해]
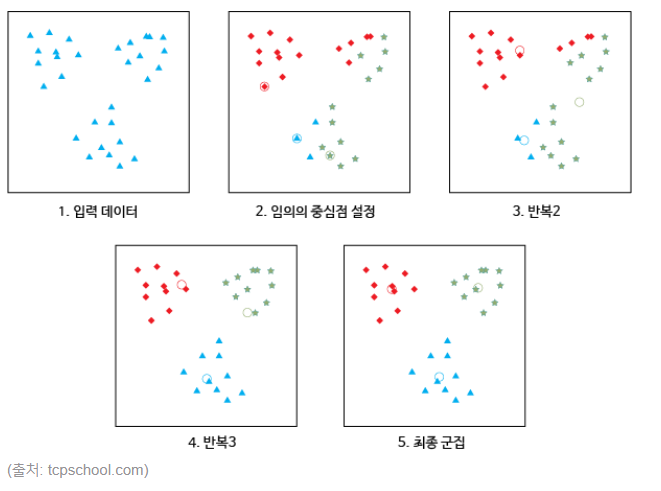
K의 값을 정한다 (몇 개의 Cluster로 나눌 것인지)
데이터셋에서 임의로 K개의 중심점을 선택.
각 점을 K개의 중심점 중 가장 가까운 점이 속한 Cluster로 assign.
각 그룹에 속하는 점들의 평균값을 새로운 중심점으로 함.
색이 변하는 점이 없을 때까지 3, 4번을 계속 반복.
군집화에서 가장 많이 활용되고 쉽고 간결하다
거리기반 알고리즘이라서 속성의 개수가 많으면 정확도가 떨어짐(PCA를 통한 차원감소 필요한 경우 있음)
몇 개의 군집을 선택해야 할지 가이드하기 어려움
KMeans클래스 사용
labels_: 각 데이터 포인트가 속한 군집 중심점 레이블
cluster_centers_: 각 군집 중심점 좌표
fit_transform: 각각의 좌표들을 기준으로 했을 때 중심과 개별 피처들의 거리
좋은 cluster: 내부 cluster에서 뭉쳐지고 외부 cluster와 떨어진 것